모니터링 시스템 구축 (Grafana + Prometheus + Spring)
서비스를 안정적으로 운영하기 위해서는 서버나 서비스에 대한 모니터링이 필수가 됩니다. 이러한 모니터링 도입과정에 대해 작성해보겠습니다.
목표
단일 Spring 서비스 환경에서 서비스 메트리과 시스템 메트릭을 모니터링 하는 환경을 구축하는 것이 현재 목표입니다.
최종적인 목표는 MS 환경을 생각하여 k8s와 각 파드에 대한 메트릭을 가져오고 이를 모니터링하고 얼럿까지 하는 것이었습니다.
(k8s를 사용해본 적이 없었고 테스트 용도로 구성해서 시도해보기에는 비용적을 부담하기에는 별로라는 생각에 local환경에서 단일 노드를 구성하여 진행해볼 생각이었습니다. 하지만 k8s의 숙련도가 낮아 먼저 단일 서비스 환경에서의 모니터링 시스템을 구축 후 점진적으로 확장하면서 해당 내용을 공유해보겠습니다.)
모니터링 구조
모니터링은 수집 -> 통합 -> 시각화 과정으로 진행된다 볼 수 있습니다.
Metric
각 서비스나 프로그램의 상태 정보로써 이를 통해 현재 시스템이나 서비스의 성능을 측정하고 보여줄 수 있게 됩니다.
- `서비스 메트릭` : Http나 JMX로 서비스 상태를 나타내는 메트릭
- `시스템 메트릭` : 파드에서 측정되는 시스템 전반의 데이터, `CPU 사용량`, `메모리 사용량`등
Metric 수집 방식
metric 수집 방식에 따라 push와 pull 방식이 있습니다.
- `push`: `모니터링 대상`이 `모니터링 서버`에 metric을 전송
- 모니터링 서버의 정보를 알아야한다.
- 각 대상자는 agent와 같은 client시스템이 있어야 한다.
- `pull` : `모니터링 서버`가 `모니터링 대상`에 요청을 보내 데이터 수집
Metric 수집 및 통합 도구
데이터 수집 및 통합에도 많은 오픈소스나 Saas제품들이 있습니다.
- 프로메테우스
- pull방식으로 metric을 수집하며, 오픈소스이다.
- 많은 자료들이 존재하여 접근하기 쉽다.
- 시계열 DB를 사용한다.
- 인플럭스 DB
- 프로메테우스와 같은 오픈소스도 제공하고 ,Sass도 제공한다.
- 성능이 좋지만 자료가 적고 구성이 어렵다.
- 데이터독
- SaaS제품으로 모니터링을 신경쓰지않기 때문에 관리하기가 쉽다.
- 다만 비용적인 측면이 존재
이 중에서 Grafana와 함께 사용하고, 오픈소스인 프로메테우스를 사용할 예정입니다.
시각화 도구
프로메테우스도 시각화를 제공해주긴 하지만 다소 다른 서비스에 비해 약하기 때문에 별도의 시각화 도구를 같이 사용합니다.
- Grafana
- 특정 소프트웨어에 종속되지 않고, 오픈소스입니다.
- 시계열 데이터 시각화에 자주 사용하게 된다.
- Kibana
- 엘라스틱서치를 개발한 엘라스틱에서 만든 시각화 도구, ELK Stack중 K가 키바나
- 따라서 엘라스틱서치와 자주 사용된다.
- 다만 Kibana는 ES의 데이터만 받을 수 있고, 프로메테우스의 데이터는 받을 수 없다.
- 따라서 프로메테우스 + Kibana를 사용하기 위해서 Metricbeat도구로 변환해서 엘라스틱서치에 전달해야함
- 위와 같은 불편함이 있지만, 시각화가 매우 좋다는 장점이 있다.
저는 이 중 Grafana를 사용할 예정입니다.
따라서

간단하게만 보면 위와 같다 볼 수 있습니다.
Spring에서 모니터를 위한 Metric 정보열기
0. Spring Boot Actuator
Spring에서는 Metric정보를 제공해주는 `Spring boot Actuactor`라는 프로젝트가 있습니다.
Spring Boot Actuactor의 경우 각 엔트포인트에 따라 서로 다른 정보를 제공해주고 있습니다.
Production-ready Features (spring.io) 에서 제공해주는 다양한 엔드포인트를 볼 수 있습니다.
대표적으로 prometheus도 제공해주고 있습니다.
1. 의존성 추가
먼저 의존성을 추가해 줍니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'
}
2. 노출시킬 엔드포인트에 대해 추가해준다.
management:
endpoints:
web:
exposure:
include: health, prometheus
엔드포인트를 추가적으로 추가하려면 include에 `,`기준으로 넣으면 됩니다.
이렇게 되면

include한 엔드포인트들이 추가됩니다.

프로메테우스는 pull방식으로 `/actuator/prometheus`에 접속하여 metric으르 가져가게 됩니다.
Prometheus 추가
먼저 프로메테우스의 기본 설정들을 추가해야 합니다. 설정 파일 이름은 `prometheus.yml`입니다.
- 서비스 메트릭 추가
global: # 공통적으로 적용
scrape_interval: 10s # interval시간
scrape_timeout: 10s # timeout 시간
query_log_file: query_log_file.log # 프로메테우스의 쿼리 기록 추가
scrape_configs:# 메트릭 수집할 대상
- job_name: 'prometheus' # 잡 이름, 단 Scope내에 하나여야 한다.
metrics_path: '/actuator/prometheus' # 접근할 주소
scheme: 'http' # 스키마
static_configs:
- targets: ['{domain:port}'] // 대상 위치
labels:
service: 'server-monitor1'
- 시스템 메트릭 추가
- job_name: 'exporter'
metrics_path: '/metrics'
scheme: 'http'
static_configs:
- targets: [ 'host.docker.internal:9100' ]
labels:
service: 'system-monitor1'프로메테우스에서 제공하는 시스템 메트릭은 window_exporter와 node_exporter가 있습니다.
- node_exporter: Unix기반
- window_exporter: 윈도우 기반
시스템들의 정보를 추가할 때 사용하면 됩니다.
프로메테우스는 더 많은 설정 기능을 제공하는데, Configuration | Prometheus 여기서 수정하면 된다.
- Docker compse 구성
위와 같이 구성 후 Compose로 한 번에 띄웠습니다.
version: '3.7'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus/config:/etc/prometheus
- ./prometheus/volume:/prometheus
ports:
- 9090:9090
command:
- '--web.enable-lifecycle'
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
networks:
- promnet
networks:
promnet:
driver: bridge
위와 같이 구성 후 실행을 하게 되면

간단한 성능 지표를 볼 수 있습니다. `Hikaricp_connections`부터 `jvm_memory_used_bytes`등 다양하게 볼 수 있습니다.
이를 좀 더 시각화를 하기 위해 Grafana까지 연동하겠습니다.
Grafana추가
그라파나의 경우 간단하게 docker로 추가가 가능합니다.
grafana:
image: grafana/grafana
container_name: grafana
ports:
- 3000:3000
volumes:
- ./grafana/volume:/var/lib/grafana
restart: always
networks:
- promnet
그라파나가 PromQL이라는 고유 쿼리 언어가 있는데, 이 언어를 통해 프로메테우스로부터 데이터를 가져오고 시각화하게 됩니다.
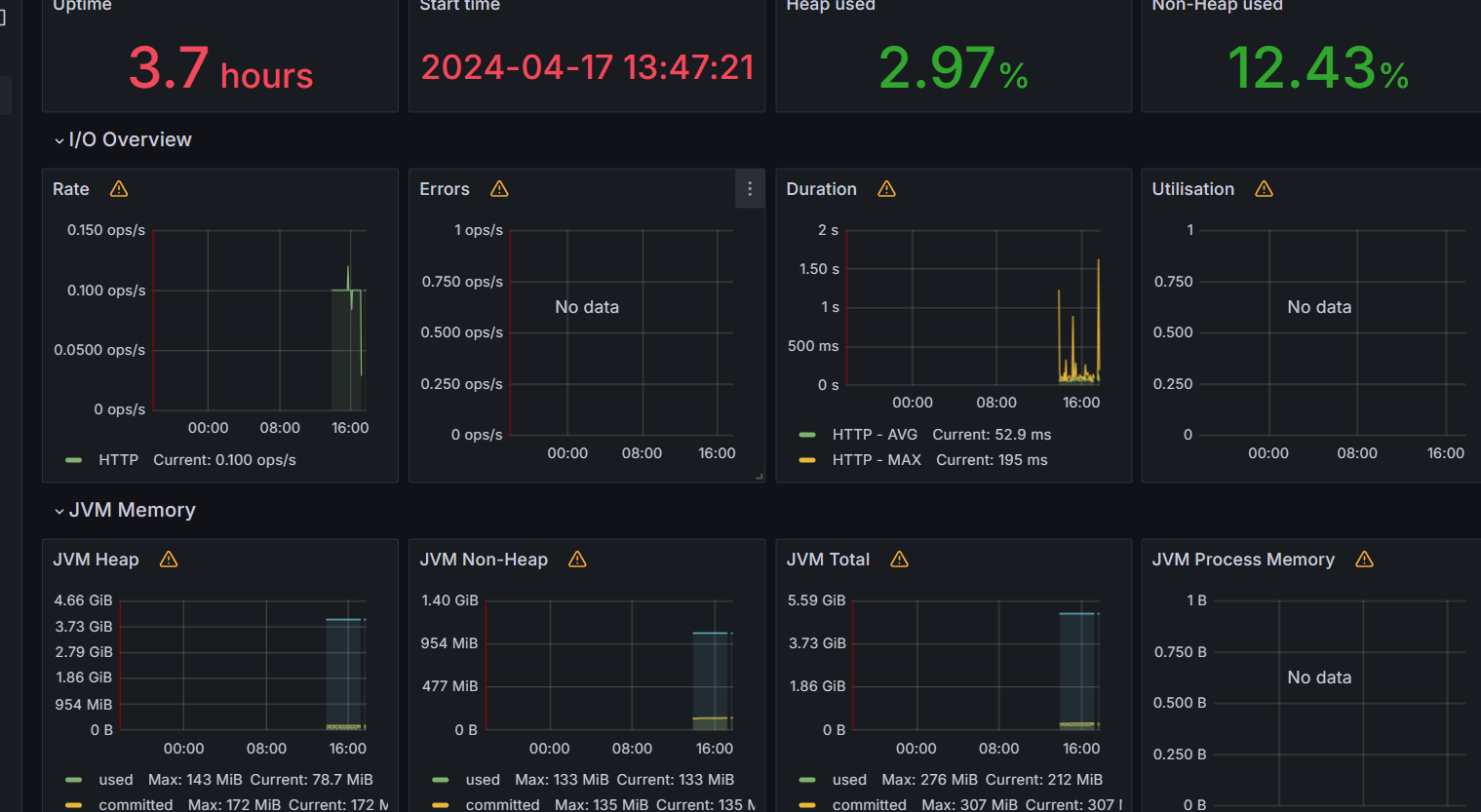
이를 통해 grafana를 컨테이너로 실행을 하고 접속을 하면 된다.
다양한 기능을 제공해주기 때문에 만져보면서 dashboard를 적용하면 되는데, 여러 json을 통해 만들어진 시각화 규격을 제공해주기도 한다.
Java의 서비스 메트릭을 시각화에서는 JVM (Micrometer) | Grafana Labs
node exporter의 경우 Node Exporter Full | Grafana Labs 와 같은 것이 있어서 맞게 커스터마이징 하면 된다.
(좀 더 다양한 자료 : Dashboards | Grafana Labs )
Data sources -> Add new Data source - > 데이터 소스 생성 후 -> Dashboard로 가서 - > 템플릿 json파일을 추가하면 된다.
결론
모니터링은 안정적인 운영을 위해 필수적이며 여러 성능 개선을 하기 위해서 필수로 사용해야하는 시스템이라 생각합니다.
앞으로의 계획
1. 모니터링을 통한 성능 개선
현재 시스템 메트릭과 서비스 메트릭으로 기존보다 더 정확한 병목지점을 잡을 수 있을 것이라 판단된다. 이를 통해 성능 개선 예정
2. 단일 시스템에서 MS에서의 모니터링
현재는 단일 시스템에 대해서만 하다보니 쉽게 가능했지만, MS로 가게 되면 k8s를 사용해야 한다. 이때 cAdvisor로 파드에 대한 성능도 추가예정
3. Batch 서비스를 위한 Pushgateway추가
프로메테우스의 경우 poll을 통해서 메트릭을 가져오게 되는데, 배치 시스템의 경우 주기적으로 실행만 하여, 기존 Polling 방식으로는 불가능합니다.
따라서 프로메테우스에서 제공하는 Pushgateway에 push되는 메트릭을 프로메테우스가 가져와서 모니터링할 수 있도록 추가 예정
4. Secure
현재는 간단하게 해놓기만 해서 보안을 적용 예정