플랫폼에 국한되지 않고어느 os위에서든 실행 가능하게 하는 프로그램이라 했는데, 정확히 무슨 뜻일까?
우리는 C나 C++을 컴파일 하게 되면 어셈블리어가 나온다 즉 여러 명령어들의 집합을 가지고 있다는 건데, 여기에는 interrupt service routine에 접근하는 명령어도 있을 것입니다. 하지만 모든 운영체제와 CPU 아키텍처마다 해당하는 명령어가 다르기 window에서 컴파일 한 파일을 리눅스에서 못돌리고, 리눅스에서 컴파일한 파일을 맥에서 못돌리게 되는 것입니다.
JVM에서 실행할 클래스 파일의 내부 구조를 분석하여 적합한 메모리 영역에 데이터를 올린다.
로드 타임 동적 로딩 : 프로그램 실행 초기에 클래스를 로딩
런타임 동적 로딩 : 프로그램 실행 중간에도 클래스를 로딩
Runtime data area
효율적으로 데이터 관리하기 위해 사용
메소드 영역
클래스가 저장되는 공간
클래스의 메타정보(클래스 변수와 메소드)
클래스가 실행하면 가장 먼저 메소드 영역에서 클래스 정보를 파싱하여 메모리 영역에 올린 후 힙 영역에 메모리를 할당
쓰레드가 공유하는 공간
힙 영역 (중요)
객체를 저장 및 공유하는 공간
동적으로 데이터가 생성되고 소멸하는 공간
쓰레드가 공유하는 공간
스택 영역
클래스가 올라간 후 메소드가 호출될 때 LIFO(Last in First out) 형식으로 데이터가 저장되는 공간
메소드 정보(매개변수, 지역변수, 복귀 주소등)이 저장됩니다.
Local variable section: Method parameter, local variables
Operand Stack: JVM의 작업 공간
Frame Data: Constant Pool, 이전 스택 프레임 정보, 현재 메서드가 속한 클래스.객체에 대한 정보
이또한 쓰레드 마다 존재하며 각 쓰레드의 스택은 함수 호출할 때마다 스택 프레임이 증가하고 종료시 감소
레지스터 영역
현재 수행할 명령어의 주소를 저장하는 공간 Program Counter(PC)
각 쓰레드는 현재 실행하고 있는 위치를 나타내야 하므로 각 쓰레드마다 있다.
네이티브 메소드 스택
자바의 경우 JVM을 통해 프로그램을 실행하므로 시스템에 직접적인 접근이 힘듭니다.
JNI API를 사용하면 자바 프로그램에서 OS시스템에 대한 접근이 가능
C, C++로 구현되어 있는 라이브러리 사용하는 경우
성능 향상을 목적으로 사용
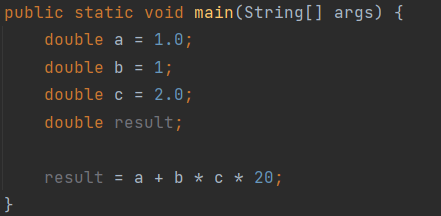
*Operand Stack 동작 과정
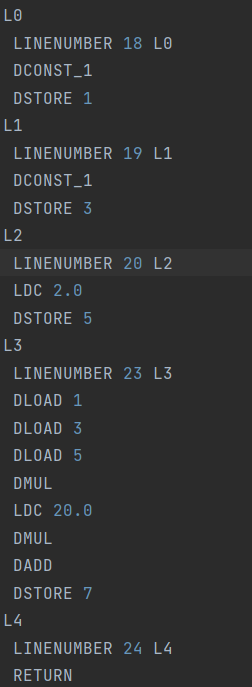
위와 같은 코드가 있다할때 index : 명령어 :: 내용 0 : DCONST_1 : 1이라는 double 상수를 Operand stack에 넣고 1 : DSTORE 1 : Operand stack을 pop하여 해당 값을 local 변수 1에다 넣는다. 2 : DCONST_1 : (0번쨰와 똑같음) 3 : DSTORE 3 : Operand stack을 pop하여 해당 값을 local 변수 3번에다 넣는다. 4 : LDC 2.0 : Run-time constant pool에 2.0 값을 가져와서 Operand stack에 넣어라 5. DSTORE 5 : Operand stack을 pop하여 해당 값을 local 변수 5번에다 넣는다. 8,9,10 : DLOAD 1 3 5 : local value 1번 3번 5번을 stack에 넣는다. 11. : DMUL : stack에서 2개를 꺼내 곱한다. ( = b* c) 그 후 다시 operand stack에 넣는다. 12. LDC 20.0 : Operand stack에 20.0값을 넣고 13. DMUL : 다시 2개의 값을 뺀 후 곱한고 ( b*c * 20) Operand stack에 넣는다. 14. DADD : 다시 2개를 뺀 후 더하고 다시 Operand stack에 넣는다. 15. DSTORE 7 : Operand stack에서 1개를 pop하여 해당 값을 local 변수 7번에 넣는다.
새로 알게된 사실 왜 JVM은 Register를 안사용하고 Stack을 사용하는 결정을 했을까?
register는 device마다 다르다 따라서 stack 대신 register를 사용하게 됐으면 구현에 관여하게 된다.
* 힙 추가
각 영역에서 가비지 컬렉터가 존재하며 Young은 수행 횟수 많고 빠르며, Old는 수행 횟수가 적고 느리다. 이렇게 하는 이유는 전체적인 효율성과 STW(Stop The World)를 줄이기 위해서입니다.
(STW는 GC가 실행되면 JVM의 다른 기능들이 일시적으로 수행이 멈추는 것을 말합니다.)
Young Generation
프로그램 내부에 코드가 실행될 때 새롭게 생긴 데이터가 저장되는 부분
Old Generation
Young 영역의 데이터가 계속 사용되면 Old 영역으로 이동하여 저장되는 부분
Permanent
클래스에 대한 정보가 저장
Execution Engine
클래스 로딩 후 각 클래스의 코드의 실행과 시스템 리소스에 대한 액세스 관리
Interpreter : 바이트코드를 기계가 이해할 수 있도록 Native Code로 바꾸며 한 줄마다 컴파일을 수행
JIT 컴파일러 : 중복되는 바이트 코드들에 대하여 매번 컴파일을 하게 되면 Running Time이 길어지므로 중복되는 바이트코드에 대해서는 JIT컴파일러를 사용합니다.
![[자바스터디] 1. JAVA와 JVM](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcfNKhV%2FbtroSWHKC3u%2FrKfz6YkkMkX9Ve5pyMjKP0%2Fimg.png)