
VGGNet

- 깊이를 깊게할 수록 더 성능에 많은 영향을 끼치는 것을 증명
- 깊이를 더 깊게하기 위해 conv filter의 크기를 줄였다 (3x3 Convolution)
- 위 결과를 통해 깊이가 깊어질수록 성능이 좋아지며
- LRN(Local Response Normalization)은 성능에 큰 영향을 주지 않았다는 사실을 알게되었습니다.
- LRN : 가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런을 억제
- 1x1 Conv Layer : Non-Linearity 증가
- 하나의 Conv층을 지나면 ReLU함수를 적용시키므로 비선형성이 증가한다.
- 이는 성능 향상으로 이어진다.
- 간단하면서 강력한 딥러닝 구조
- 작은 필터 사이즈도 깊게 쌓으면 충분히 효율적인 특징 추출이 가능
GoogleNet ( Inception V1 )
- AlexNet보다 12배나 적은 파라미터로 더욱 좋은 성능을 보인다.
- 연결이 듬성듬성있기에 파라미터 수가 적고, 과대적합을 방지하는 효과가 있다.
- 행렬 연산에서는 데이터가 sparse해지는 현상을 방지하는 것을 목표로 한다.
- 완전 결합에서 sparse로 변경한 또 다른 이유 : 네트워크가 커질수록 캄퓨터 자원의 사용량 증가
- 1x1 필터의 합성곱층
- 네트워크 크기 제한
- 병목현상을 제거하기 위한 차원 축소
- [1x1, 3x3], [1x1, 5x5]가 하나의 합성곱 층으로 동작
- 각 연산은 병렬적 수행 후 Concat으로 합침
- 모든 합성곱 층은 ReLU 활성화 함수를 사용
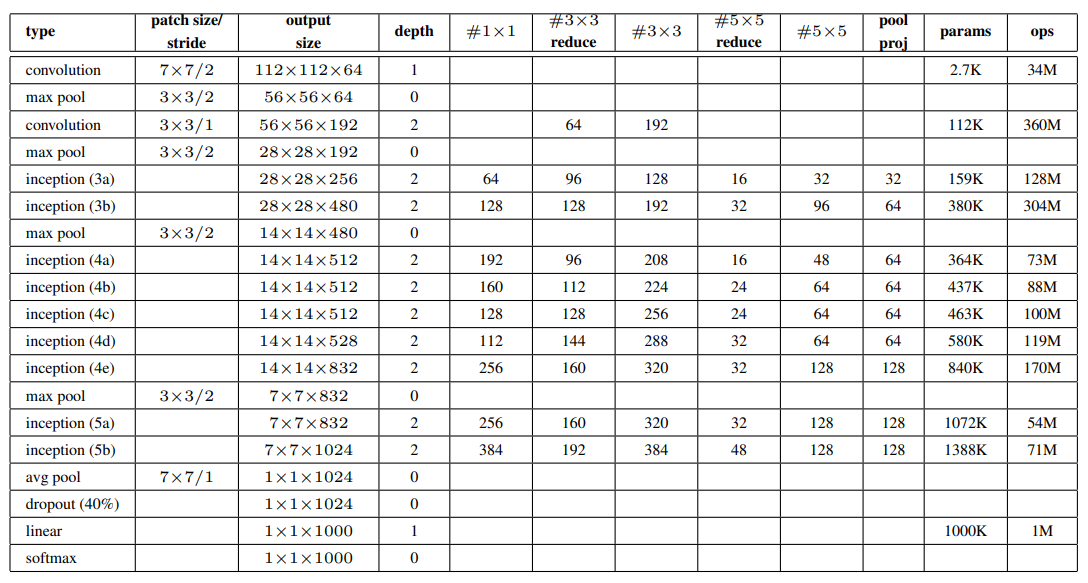
- 위 표의 reduce는 각 필터앞에 오는 1x1필터의 채널 수를 나타낸다.
GAP(Global Average pooling) & FC(Fully connected layer)
마지막 pooling이 average pooling layer이다. 이전 layer에서 추출된 feature map을 각각 평균 내어 1차원 백터로 만들어 가중치를 없앤다.
fully connected layer의 경우 dense형태로 가중치가 7 * 7 * 1024 * 1024가 된다.
또한 평균을 취한 pooling으로 특이값 입력에 대해 강하다
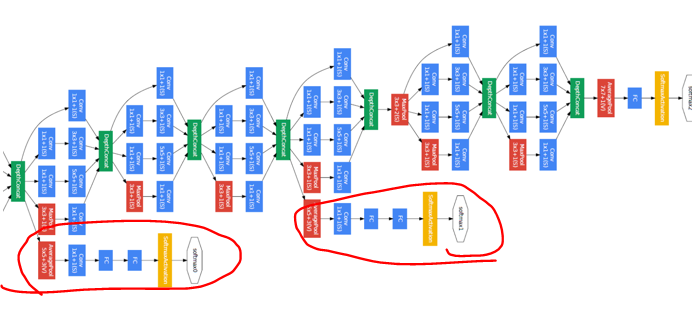
Auxiliary Classifier
gradient가 손실되는 현상인 Vanishing Gradient 문제는 레이어가 깊어지면서 발생하게 되는데 이를 방지하기 위해 추가하며 Test에는 사용하지 않는다. Auxiliary Classifier를 중간 마다 추가하여 결과를 출력해 backpropagration을하여 gradient가 전달될 수 있게 하였다.
'인공지능' 카테고리의 다른 글
| [딥러닝] 딥러닝을 위한 GPU 셋팅 with VSC (0) | 2022.04.29 |
|---|---|
| DL - Text Detection (EAST) (0) | 2022.04.04 |
| 딥러닝 - 합성곱 신경망 & AlexNet (0) | 2022.03.27 |
| 딥러닝 - 다중 퍼셉트론 (0) | 2022.03.21 |
| 딥러닝 - 로지스틱 & 소프트맥스 & 크로스 엔트로피 (0) | 2022.03.15 |