
MLP(다중 퍼셉트론)
- 기존 1개일때는 구분하기 힘들지만, 2개 이상이면 3개의 영역으로 구분 가능
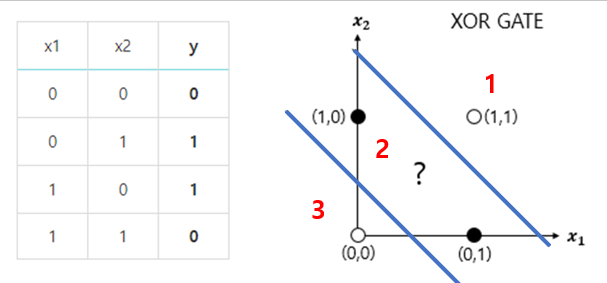
- 입력 층(통과) 1개 + 출력 층(마지막) 1개 + 은닉 층(TLU) 1개 이상
- 하위 층: 입력 층에 가까움, 상위 층: 출력 층에 가까움
- 편향 뉴련: 출력 층을 제외하고 전부 존재
- feedforward neural network(FNN): 입력에서 출력으로 한 방향으로만 흐른다.
- DNN(Deep neural network) : 은닉 층을 여러 개 쌓아 올린 인공 신경망
Backpropagation(역전파)
- 다중 퍼셉트론을 훈련할 훈련 알고리즘, 데이비드 루멜하트, 제프리 힌턴, 로날드 윌리엄스가 공개
- 네트워크를 정방향, 역방향 1번씩 통과하여 모든 모델 파라미터의 오차를 줄이기 위한 가중치와 편향값의 변화를 알 수 있다.
- 즉, gradient를 구할 수 있다.
알고리즘 과정
- 에포크: 한 번에 하나의 미니배치씩 진행하여 전체 훈련 세트를 처리한다. 여러번 반복하게 되는데 이 과정을 에포크라한다.
- 정방향 계산(Forward pass) : 입력 층 -> 은닉 층 -> 출력 층
- 역방향 계산을 위해 중간 계산 값 모두 저장
- 네트워크의 출력 오차 측정
- Loss function 사용하여 기대 출력과 네트워크의 실제 출력 비교 후 오차 측정 값 반환
- 각 출력 연결이 이 오차에 기여하는 정도 계산
- Chain rule(연쇄 법칙): 해당 단계 수행을 위한 규칙
- 이전 층의 연결 가중치가 이 오차의 기여 정도에 얼마나 기여했는지 측정(입력 층까지 역방향 지속)
- 이를 역방향 계산이라한다.
- gradient를 확정한 후 gradient descent(경사 하강법)을 수행한 후 네트워크에 있는 모든 연결 가중치 수정
(제대로된 훈련을 하기 위해서는 은닉 층의 연결 가중치는 랜덤하게 초기화 해야한다. )
역전파
- 활성화 함수
- 시그모이드 : 로지스틱 함수
- ReLU : -1 ~ 1 사이의 범위
- 함수 값이 0보다 클 때 : 기울기 항상 1, 오차 그레이디언트 그대로 역전파
- 함수 값이 0보다 작거나 같을 때 : 항상 0, 역전파하지 않는다.
- tanh(하이퍼 볼릭 탄젠트) : z = 0 에서 미분 불가능, 출력에 최대값이 없다.
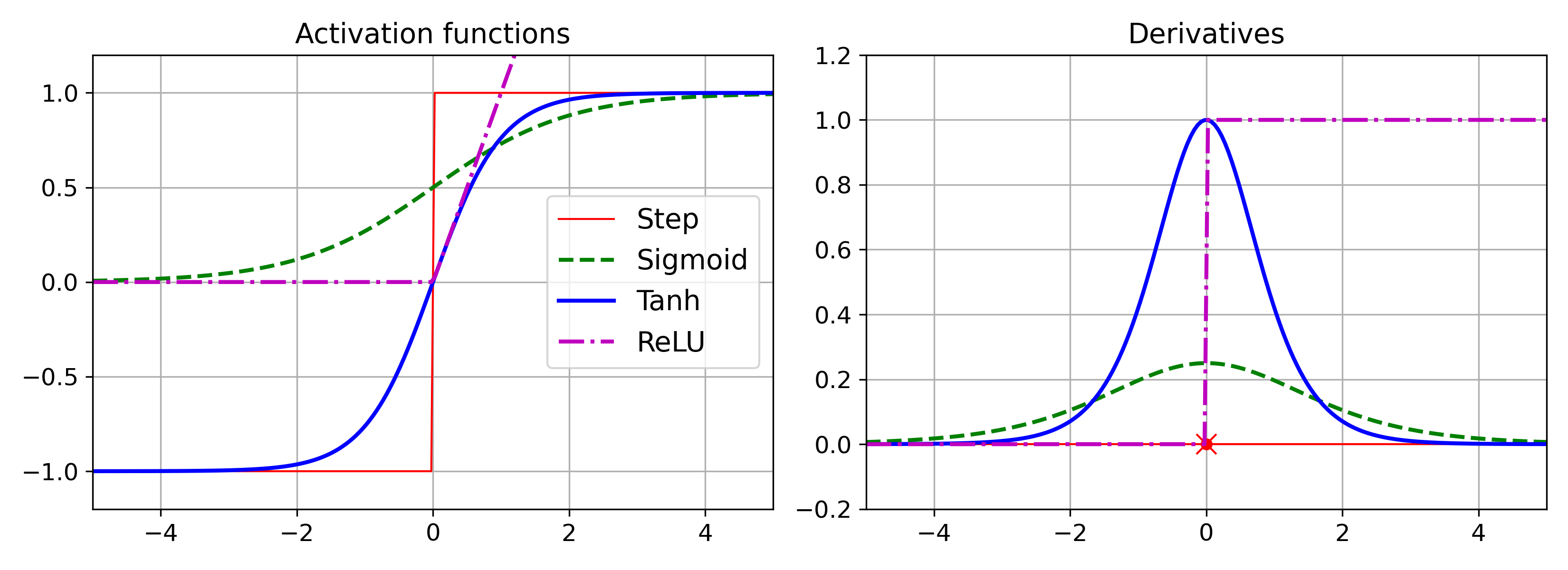
활성화 함수의 필요성:
선형 함수는 여러 개의 선형 변환을 거쳐도 동일한 선형 함수가 될 뿐입니다.
Ex) f(x) = ax + b에서 다른 선형 변환(cx + b)을 거치면 똑같은 ax + b가 나옵니다.
따라서 층 사이에 비선형성을 추가해야 여러 층으로 문제를 풀 수 있습니다.
다층 퍼셉트론 - 회귀
- 은닉층:
- ReLU
- 출력 층:
- 출력으로 모든 범위의 값을 얻기 위해서 출력 뉴련에 활성화 함수 적용 안한다.
- 출력이 항상 0 이상이면 - ReLU 활성화 함수 사용
- 특정 범위의 값 - 로지스틱(시그모이드), 하이퍼볼릭 탄젠트 함수 사용
- 손실 함수 - 기본적으로 MSE
- 이상치 존재 = Huber(평균 절대값 오차 + 평균제곱오차(MSE)) or 평균 절대값 오차
다층 퍼셉트론 - 분류
- 다중 이진 분류를 위해 출력층에서 소프트 맥스 활성화 함수를 사용해야 한다.
- 손실 함수 - 크로스 엔트로피 사용
'인공지능' 카테고리의 다른 글
| 딥러닝 - VGGNet, GoogleNet (0) | 2022.03.28 |
|---|---|
| 딥러닝 - 합성곱 신경망 & AlexNet (0) | 2022.03.27 |
| 딥러닝 - 로지스틱 & 소프트맥스 & 크로스 엔트로피 (0) | 2022.03.15 |
| 딥러닝 - 다항 회귀 (0) | 2022.03.15 |
| 딥러닝 - 머신러닝 기본 프로세스 (0) | 2022.03.14 |